介绍使用 Barracuda 在 Unity3D 中运行机器学习模型。这允许您在 Unity 视频游戏引擎中以 onnx 的格式运行大多数的机器学习模型,以便在 Android 或 iOS 上提供跨平台支持。这个教程是我在学习过程中的学习分享,适合新手作为一个学习参考。

(已过时) 可以查看一个更为泛用的新教程(性能更强,实时检测,支持yolo模型热插拔):
Unity中实现Yolo的实时目标检测
在这个Unity 教程中,我将介绍使用 Barracuda 在 Unity3D 中运行机器学习模型。这允许您在 Unity 视频游戏引擎中以 onnx 的格式运行大多数的机器学习模型,以便在 Android 或 iOS 上提供跨平台支持。这个教程是我在学习过程中的学习分享,不会涉及到机器学习的内容以及集成Unity3D过程中很深的内容,很适合新手作为一个学习参考。
前言
最近我暂时搁置了我正在独立开发的游戏,因为我想让自己的独立作品包含一些新鲜玩意。我一直尝试在Unity3D中集成一个节奏识别的深度学习网络,我参考并且尝试了一些解决方案,但是都不能达到一个类似于Conda的环境支持。当然,开发环境中运行深度学习已不是什么新鲜事了,但是在runtime中运行任意一个深度学习网络,在玩家游玩的过程中使用各式各样的机器学习模型才是我所追求的。
解决方案对比
我尝试了一些Unity3D官方提供的和其他我所找到的解决防范,下面简单列举一下它们的优劣:
- Python for unity:
- 使用简单,官方提供了完整的安装包,可以直接安装
- 支持Python的第三方库,引用或者在项目路径添加 site-packages 即可
- 不支持Runtime和成品打包,代码属于一个UnityEditor的扩展
- 无法更改各种Python包的版本,会出现各种问题
- Pythonnet:
- 它属于Python for unity的外源,Python for unity就是使用了这个库开发的,可以在Unity3D的Github上找到一摸一样的fork源码,属于原生的Python for unity了
- 它的优劣和 Python for unity 类似
- IronPython:
- IronPython 是Python在.NET平台上的实现,支持Runtime集成
- IronPython 其实也需要引入程序集和DLL,需要熟悉IronPython的内部实现
- 对于初级开发者而言,它比较适合小体量的Python脚本
- 不太适合深度学习的框架
- ML-Agent:
- Unity3D官方的机器学习解决方案,安装简单,有大量的教程的文档、
- 支持和Anaconda协同环境(仅开发环境,不支持Runtime)
- 脱离了python的机器学习框架,Unity为了使它对非深度学习开发者更易用,做了自己的封装,使用了自己一套逻辑,以前使用的应该是TensorflowSharp做接口,用C#写逻辑。
- 虽然名字是ML-Agent,但是它并不能支持大部分机器学习的内容,更像是一些特定的强化学习模型,没有很强的定制化区间,而且除了Unity自己,其他开发者很少用这套东西做开发
- 不适合Python深度学习模型的集成,虽然你可以用Conda环境,但是想要把Conda环境中你训练好的模型直接做集成是不支持的。
- Barracuda:
- Barracuda 是最贴近大多数机器学习集成的一套东西。使用简单,官方提供了完整的安装包,可以直接安装
- 支持比较多的模型:全卷积神经网络,全稠密网络,Tiny YOLO等,这里还支持所有的ML-Agent网络(Unity还是要支持自己的工具的)
- 适用于很多onnx网络
- 支持Runtime集成,用C#和模型做了输入和输出的接口
- 缺点就是它支持的网络取决于onnx模型,全卷积神经网络,全稠密网络等,能做的事情比较集中,图像识别,图像风格转换,表情识别等最经典的模型更适用一些,不支持其他新兴网络,比如stable disffusion等扩散模型和其他模型。
- 自行封装DLL:
- 这部分看个乐就好了,独立开发者用的小型DLL还行,针对某一个网络做自己的DLL还是比较容易实现的,需要对DLL部分的知识很清楚…
- 如果你想集成类型多一些的神经网络,不要想了,Unity做了好几年的Barracuda,ML-Agent都没能解决,独立开发者还是不要尝试了。
//TODO : 如果有需要的话,我可以单独把每一个解决方案都写一下大致的集成教程,那可能涉及到很多零散的内容。
准备深度学习模型
我不准备在这里讲很多机器学习的内容。这里你需要将深度学习模型转换为onnx的格式,这部分可以看pytorch或者onnx的教程。
内容包含:ImageClass.onnx (深度学习模型) labels_map.txt (识别标签)
我使用的是一个很简单的onnx模型,它是一个参数比较少的CNN模型,因为移动端的计算性能远低于PC或者集群服务器。该模型的而且在少量计算资源的情况下可以维持在30ms内识别结果。
这个模型训练使用到的数据集是ImageNet数据集,包含了1000个物体的标签,我通过电脑跑这个模型,并且使用了一些经过裁剪的图片时,准确率大概在80%左右。值得注意的是,因为手机像素以及其他因素,摄像头得到的图像识别率会降低一些,识别准确率和手机摄像机拍摄的照片质量有很强的联系。
我们需要用到的就是这个模型的输入和输出。
- 输入:float32[1,224,224,3] (batch_size为1的224*224的RGB图像)
- 输出:float32[1,1000] 这是将索引映射到标签的分数,分数越大,对应标签的可能性越大
Unity的场景设置
Unity场景的设置很简单,我们只需要一个Canvas:其中有一个RawImage用于显示手机摄像机返回的图像,还有一个Button来交互,button上的文字就是识别的结果。除此之外,我还设置了一个空物体来存放推理和识别的脚本。
关键脚本与流程
手机摄像头的显示
首先是声明一个RawImage用来存放和显示摄像头的图像,这里我们额外设置了一个AspectRatioFitter组件用来设置将RawImage的比例设置成与手机屏幕比例一致。
然后我们通过使用WebCamTexture来读取摄像机的画面。(这里需要额外注意,可以通过设置RawImage的Z轴旋转为-90,否则手机屏幕会是翻转的。)
void Start()
{
rawImage = GetComponent<RawImage>();
fitter = GetComponent<AspectRatioFitter>();
InitWebCam();
if (webcamTexture.width > 100)
{
fitter.aspectRatio = (float)webcamTexture.width / (float)webcamTexture.height;
}
}
void InitWebCam()
{
string camName = WebCamTexture.devices[0].name;
webcamTexture = new WebCamTexture(camName, Screen.width, Screen.height, 30);
rawImage.texture = webcamTexture;
webcamTexture.Play();
}
图像数据的预处理
得到原始的摄像机的图像之后,第一步要做的就是裁剪和重采样。因为我们的模型需要的输入是float32[1,224,224,3]
- 首先第一个参数代表batch_size是1,我们每次读取一张图片就好
- 第2,3个参数224,224代表的是图像的大小
- 第四个参数3代表的是RGB通道
所以我们需要把图像裁剪成正方形的,并且还需要对图像进行DownSample, 因为我们的输入需要的像素是224*224的,所以尽量保证数据源的像素高的同时,还需要把图片尽量不损失内容的情况下DownSample成我们需要的形状。
首先我们新建一个renderTexture用来存放结果,这里我们使用的格式是ARGB32. 然后通过Graphics.Blit函数,使用shader的方式来进行图像的裁剪和定位以及次采样. 然后我们通过AsyncGPUReadback来把GPU处理的renderTexture数据传到CPU用来计算。
public void ScaleAndCropImage(WebCamTexture webCamTexture, int desiredSize, UnityAction<byte[]> callback)
{
this.callback = callback;
if (renderTexture == null)
{
renderTexture = new RenderTexture(desiredSize, desiredSize, 0, RenderTextureFormat.ARGB32);
}
scale.x = (float)webCamTexture.height / (float)webCamTexture.width;
offset.x = (1 - scale.x) / 2f;
Graphics.Blit(webCamTexture, renderTexture, scale, offset);
AsyncGPUReadback.Request(renderTexture, 0, TextureFormat.RGB24, OnCompleteReadback);
}
这里我们使用了GetData
void OnCompleteReadback(AsyncGPUReadbackRequest request)
{
if (request.hasError)
{
Debug.Log("GPU readback error detected.");
return;
}
callback.Invoke(request.GetData<byte>().ToArray());
}
转化成模型可接受的数据还需要一个步骤就是把RGB[0,255] –> [-1,1]进行一个域转换,然后我们使用到了Barracuda提供的Tensor数据结构。
这一步就可以直接让Unity中的数据直接和我们的深度学习模型进行交互了。不过具体的数据的格式还是要看模型需要怎样的输入了,这部分比较个性化,不过基本上都是张量…
Tensor TransformInput(byte[] pixels)
{
float[] transformedPixels = new float[pixels.Length];
for (int i = 0; i < pixels.Length; i++)
{
transformedPixels[i] = (pixels[i] - 127f) / 128f;
}
return new Tensor(1, IMAGE_SIZE, IMAGE_SIZE, 3, transformedPixels);
}
模型的推理
首先引用我们需要的模型文件,这是Barracuda提供给我们的简单应用。ModelLoader允许我们引用模型,WorkerFactory允许我们构建推理引擎。这里WorkerFactory.Type.ComputePrecompiled使用的是GPU推理,当然你需要根据平台和模型来决定最适合的引擎,有基于CPU的引擎等。
var model = ModelLoader.Load(modelFile);
worker = WorkerFactory.CreateWorker(WorkerFactory.Type.ComputePrecompiled, model);
然后我们最核心的处理流程来了:
- 调用TransformInput生成输入的tensor;
- 然后调用 worker.Execute 可以使用神经网路进行推理;
- 然后worker.PeekOutput得到largest output;
- 根据output得到最大的index,我们自定义一个LoadLabels函数得到index对应的标签,这个标签就是我们想要的结果。
- 最后记得手动释放tensor,因为Unity的GC接管不了这些资源。
IEnumerator RunModelRoutine(byte[] pixels)
{
Tensor tensor = TransformInput(pixels);
var inputs = new Dictionary<string, Tensor> {
{ INPUT_NAME, tensor }
};
worker.Execute(inputs);
Tensor outputTensor = worker.PeekOutput(OUTPUT_NAME);
//get largest output
List<float> temp = outputTensor.ToReadOnlyArray().ToList();
float max = temp.Max();
int index = temp.IndexOf(max);
//显示结果输出到UI Text
uiText.text = labels[index];
//dispose tensors
tensor.Dispose();
outputTensor.Dispose();
yield return null;
}
根据Index得到标签结果
在一开始我们可以设置一个string[] 存放结果标签,使用index来查表获得结果即可。流程从上一部分的显示结果输出到UI Text开始。
void LoadLabels()
{
// 得到index对应的标签
var stringArray = labelAsset.text.Split('"').Where((item, index) => index % 2 != 0);
labels = stringArray.Where((x, i) => i % 2 != 0).ToArray();
}
为了节约资源,我使用Button调用函数,这样我们不必每一帧都执行模型推理,其实实时识别是可以做到的,但是手机的帧率会急剧下降,所以还是建议使用button来决定什么时候进行推理识别。
结果 & Outro
经过测试,我的手机毫无压力的得到了不错的识别结果。
注:在代码里我强制使用了30帧来节约资源。识别的结果如下(重做了新的UI界面):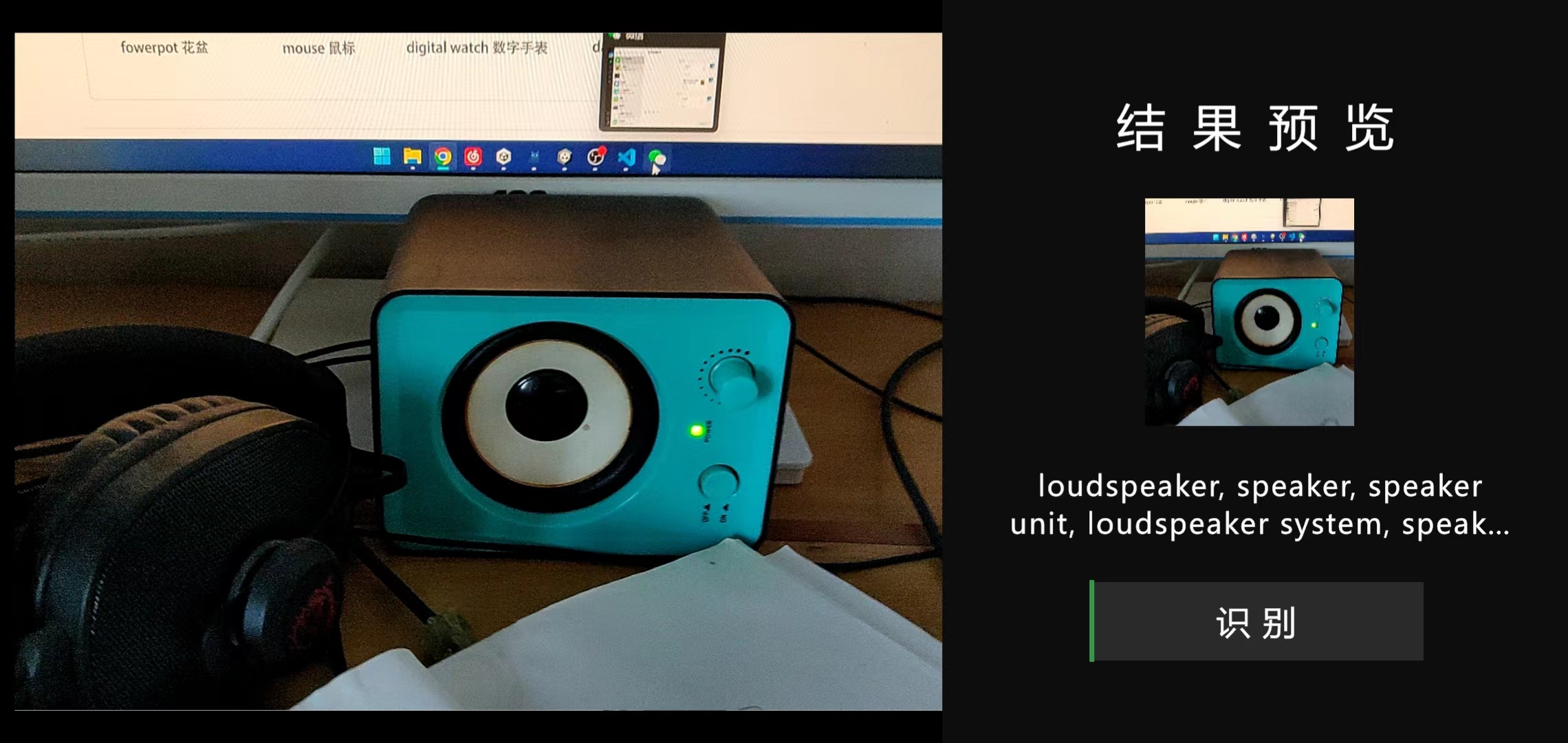
未来的方向
其实这只是一个很普通简单的例子,真正有价值的是,在游戏引擎里面使用恰当的机器学习模型能让游戏变得更加有趣。能在Unity3D里面实现物体识别,短期就能实时其中里面做到物体追踪,图像分割。更加长远的目标是用让深度学习的模型来构建游戏内容,比如一个更智能的卡牌游戏AI,比如一个完全由机器学习模型生成的NPC,或者NPC讲故事时,故事的文本完全由模型生成。这样一来,游戏的随机性会得到质的飞跃。
我近期的目标是把节奏检测的神经网络集成到我的独立demo里面,我想让玩家能够在一个完全支持自定义的泛音游里面找到自己的乐趣。不过想要把conda环境和神经网路的各种依赖关系无缝集成到Unity\Unreal或者其他引擎里面去,还是需要很长一段路要走。
关于这个简单的图像识别Demo,它所有的代码都是开源的,请在下面的地址下载工程文件以及打包好的apk文件, (我只在自己的安卓10的Oneplus 6上做过测试,文件不支持IOS):